Improving AI/ML Image Processing to Tackle Bottlenecks of Fisheries Data
May 23, 2023
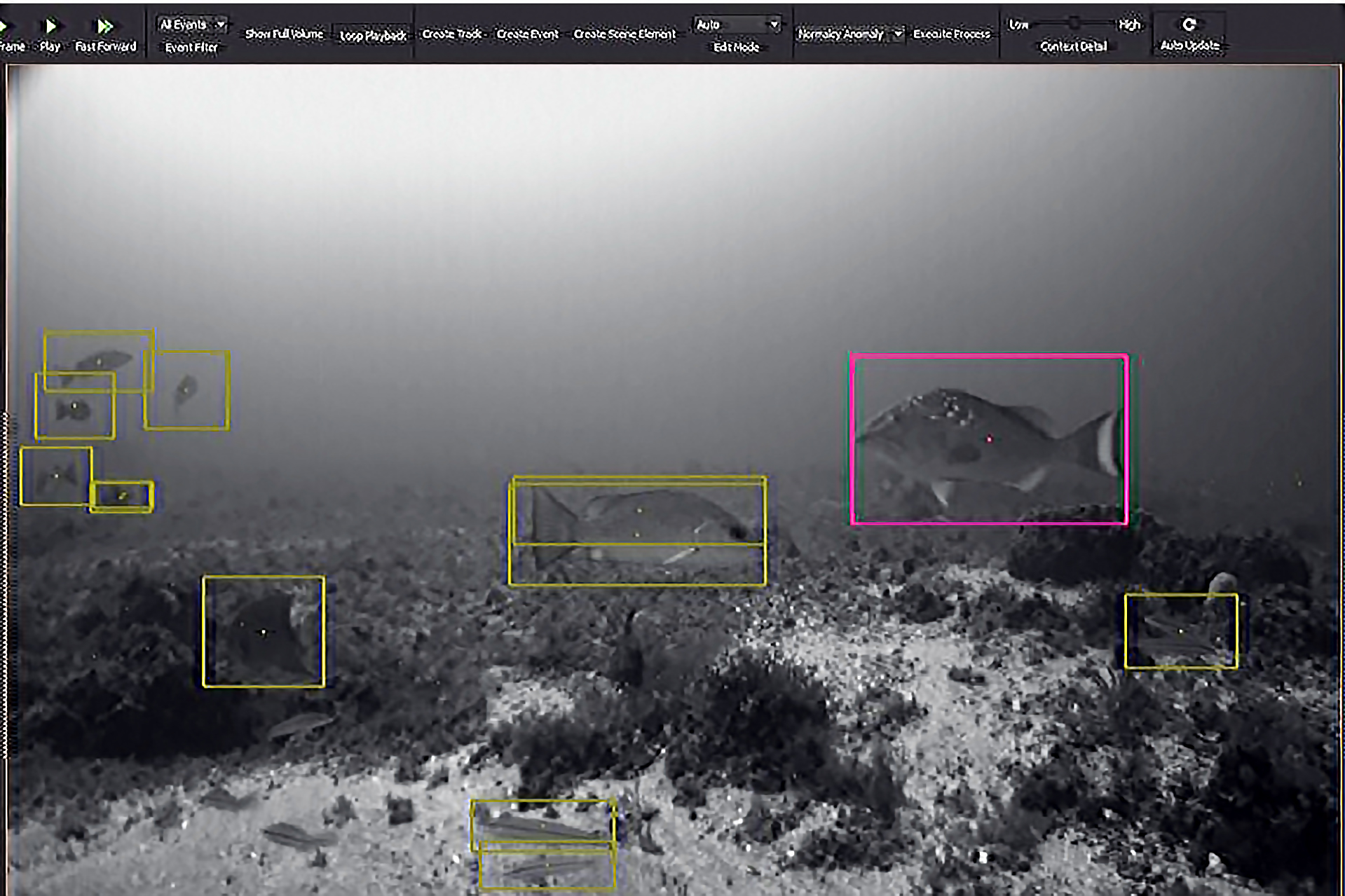
Example of analysis using VIAME and its deep learning algorithms to detect and identify multiple species of fish in one image. VIAME now displays the Latin names for each species that it identifies. Credit: NOAA Technical Memorandum NMFS-PIFSC-83.
There is a lot of buzz right now around the explosion of efficiency possibilities fueled by Artificial Intelligence (AI) and Machine Learning (ML). These cutting-edge technologies are being researched by the National Marine Fisheries Service (NMFS), a division in the National Oceanic and Atmospheric Administration (NOAA), to automate image processing of video collected during research surveys that provide critical information for the stewardship of our nation's ocean resources and habitat.
Toward this end, scientists and engineers with the NMFS; Northern Gulf Institute; Technical and Engineering Support Alliance, LLC; and Kitware, Inc. are advancing AI/ML applications for marine environmental monitoring. Their work includes investigating the precision, accuracy, and reliability that computer vision algorithms detect, count, and classify fish in video and developing frameworks to build trustworthy automated image processing models.
Their findings and steps for moving forward with AI/ML to gain efficiencies in effort, cost, and timeliness with fisheries image processing were recently published in
Frontiers of Marine Science.
Background
The NMFS monitors fish populations and their habitats because of threats to health and sustainability from stressors such as overfishing, climate change, hypoxia, habitat loss, and pollution.
"Fish populations in the Gulf of Mexico are partly managed by large-scale surveys that utilize cameras to view and count fish in important habitats along the coastal shelf, such as the 360-degree camera arrays used for the annual Reef Fish Video Survey," explained Fisheries Biologist Jack Prior. "This video results in a large amount of data that takes time to watch and sort manually."
For example, two Gulf of Mexico fishery surveys resulted in ~1,000 hours of video and ~30 TB of data in just one year. Add that to data from surveys conducted across U.S.-managed waters for decades along with ongoing surveys and those planned, and it is obvious that the data dilemma is escalating.
To address this situation, the NMFS funded the
Automated Image Analysis Strategic Initiative, which resulted in the
Video and Image Analytics in the Marine Environment (VIAME) software, intended to speed up processing and quality control and decrease the time to get usable data. VIAME uses deep-learning neural network algorithms trained by high power computer graphics processing units to detect and classify a wide variety of natural marine resources.
"These algorithms are 'taught' by providing a training library of images where each fish within each frame is labeled by its Latin species name," said Prior. "A library of over 600,000 labeled individuals has been developed to train these models."
Challenges
Fish counts and classifications have been derived manually for decades. These vital time-series data are compared against current data to identify trends and patterns that inform fishery management actions. Therefore, AI/ML model architectures and algorithms need to closely emulate human efforts for comparison compatibility. There also needs to be precision and agreement across models and across laboratories, video annotators, video archives, and data sets.
The inevitable differences between human and automated image processing must be analyzed, evaluated, and compensated for if necessary. Establishing standardized metrics for accuracy and precision in AI/ML models can help. For example, parameters for accuracy can be used to determine which datasets to entrust to automated processing (fish that AI/ML handles at higher accuracy levels) or that require human supervision (fish that AI/ML handles at lower accuracy levels).
Research
To facilitate analysis, evaluation, and improvement of AI/ML image processing models, the team developed an automated workflow that trains algorithms to reliably produce data equivalent to manual processes using metrics that can track over time as the models evolve or camera technology changes.
The workflow's framework is based on methods and metrics for otolith aging that gauge model performance by comparing automated counts to validated counts as a complement to traditional metrics like mean average precision. The logic for drawing from this existing structure is that counting fish in a video is akin to counting otolith rings. Each read of a video, like each read of an otolith, should produce similar results and thus provides a means to evaluate precision.
The team applied the automated workflow to train the latest versions of the VIAME models and tested them on 23 commercially and ecologically important species observed during Gulf of Mexico reef fish surveys. They assessed the quality of the newly trained models and the confidence thresholds assigned to fish detections, counts, and classifications by comparing the proportion of false-positive rates and percentages of exact count agreement, count agreement within 1-2 counts, and model variability against ground-truthed data at matching survey sites.
Results
Performance of the VIAME models was mainly influenced by the number of classification-specific annotations used in training, the frequency of certain behaviors, and by fish density. False-positive detections were greatly reduced with a second iteration of model training.
"Increasing the amount of data (labeled pictures of fish) that goes into teaching these models to recognize and count targets across video frames, leads to improvements in the model performance," explained Prior. "But for some species, such as smaller targets that form schools of fish, model performance did not improve as much and will require further solutions."
For example, Red Snapper (Lutjanus campechanus) were shown to be reliably counted by the models with up to 10 individuals in a single frame. "With further testing, these algorithms could soon be ready for implementation into the full management process," stated Prior.
However, for some species, model precision remained poor even after increasing the number of labeled fish pictures, especially for schooling or shoaling species (e.g., Vermilion Snapper) and for cryptic and small fish (e.g., Lionfish, Butterflyfish) as they were seen as background because they looked like the habitat (e.g., soft coral).
The otolith aging method uses ~10% as acceptable for model variation; however, in this application, only 2 of the 23 fish species fell in that range and only 7 of the 23 were below 25%. Acceptable ranges have not been determined for this new application and presents an area for further investigation.
Next
The VIAME model is precise enough to begin a semi-automated video filtering approach for select species, providing usable datasets more quickly, reducing possibility of reader bias, and allowing for targeted manual annotation.
For example, if fisheries management asked for Red Snapper data, 90% of the automated image reads would be reliably annotated, leaving only 10% for manual annotation (at this early stage, QA/QC needs to be completed for all annotations). But, if management asked for Vermilion Snapper data, that video would be pulled for 100% manual processing.
"While the models show promising accuracy for some species, model performance needs improvement for species at lower accuracy levels," noted Prior. "Additional ways to measure model performance are needed that integrate with current standards and methods of counting fish that help assess fish populations."
He said doing so will help models fit in as tools for established surveys with time-series data, such NOAA's annual Reef Fish Video Survey going on for 30+ years. Model performance needs to be tracked over time as improvements and developments are made and when applied to locations where habitats, water quality, or types of fish seen are different.
Actions to improve model performance include adding more labeled pictures of fish in training libraries to establish reliability limits for most species. Other AI tools – active learning algorithms – may help to calibrate model performance by directing training toward the most important classes and selecting priority images for training. Sharing models and imagery, when possible, can foster research collaboration on emerging tools such as habitat classification models or automated fish measurement.
The framework developed in this study is a first step toward tracking model performance, establishing best practices to integrate automated image processing into existing standard operating procedures, and providing precision metrics for calibrating and tuning ecosystem models. The framework can be adapted to any type of machine learning model for use beyond fisheries, contributing to globally cooperative systems of trustworthy AI.
AI/ML image processing has significantly progressed in utility, enough that their integration into post-processing pipelines, which is necessary for further analysis and optimal use of datasets, is a logical step for the next 5-10 years.
By
Nilde Maggie Dannreuther, Northern Gulf Institute, Mississippi State University (NGI/MSU) and
Jack Prior, NOAA Southeast Fisheries Science Center and NGI/MSU.
The
Northern Gulf Institute is a NOAA Cooperative Institute with six academic institutions located across the US Gulf Coast states, conducting research and outreach on the interconnections among Gulf of Mexico ecosystems for informed decision making.
